Every company building AI agents today faces the same dilemma; should we use Retrieval-Augmented Generation (RAG) or skip it altogether? The choice isn’t just technical; it defines how reliably your agents understand and use your data.
The impact runs deep. It affects accuracy, hallucination rates, scalability, and even long-term maintenance costs. Many AI systems that sound impressive at first fail quietly in production because they never truly ground their responses in real data.
Choosing the wrong approach can create an illusion of intelligence. Without retrieval, models hallucinate. With poor retrieval, they choke on irrelevant context. Getting this balance right is what separates smart demos from scalable products.
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is a framework that helps large language models (LLMs) use real, external information instead of relying only on what’s stored in their parameters. Instead of generating answers from memory alone, RAG retrieves relevant data from connected sources like databases, documents, or APIs before responding.
In simple terms, RAG gives AI models a “research step.” It’s built around four key layers: indexing, where your data is stored and embedded; retrieval, which fetches context; augmentation, which injects that context into a prompt; and generation, where the LLM crafts the final answer.
This approach dramatically reduces hallucinations and adds transparency. Since every response is backed by real, retrievable data, teams gain both accuracy and provenance seeing why an agent gave a certain answer.

What Does “No-RAG” Mean in This Context?
When people talk about No-RAG, they’re referring to AI systems that generate answers without fetching new data. These are pure LLMs or memory-based models, relying entirely on what’s already encoded in their parameters.
Some use latent or embedded memory to retain knowledge between sessions, but they don’t pull fresh or external information. This makes them fast and lightweight which is perfect for stable, closed-domain tasks.
The trade-off comes with scope and accuracy. Without retrieval, models struggle with data freshness and domain coverage. They perform well within trained knowledge but fall short when real-world information changes.
RAG-Enabled Agents vs Traditional Agents - Key Differences
Not all AI agents think the same way. Some rely purely on what they’ve been trained to remember, while others dynamically search for fresh information before answering. This is where RAG-enabled agents and traditional agents part ways.
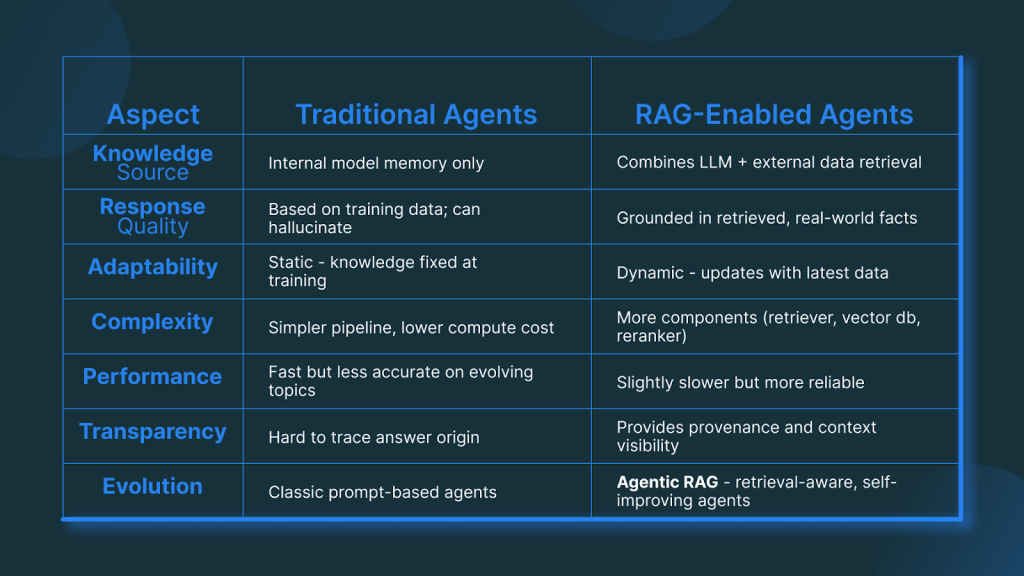
Agentic RAG represents the next step: agents that don’t just retrieve information, but also decide when and what to fetch dynamically. This allows them to reason, plan, and use data intelligently rather than blindly generating text.
When to Choose RAG and When to Avoid It
When to Choose RAG
Use Retrieval-Augmented Generation (RAG) when your system needs to stay current and context-aware. It’s ideal for data-heavy, ever-changing environments where grounding matters.
- Large or constantly updating knowledge bases (e.g., documents, wikis, or CRMs).
- Domains where factual accuracy and provenance are essential.
- Use cases requiring multi-source reasoning such as research assistants, customer support, or analytics bots.
- When scaling knowledge is cheaper than retraining models.
When to Avoid RAG
RAG isn’t always the best fit. Some tasks need speed and simplicity over deep grounding.
- Small, static datasets that rarely change.
- Latency-sensitive applications like chat widgets or real-time assistants.
- When infrastructure or API overhead makes retrieval too costly.
- If your data is private, fragmented, or not yet ready for vectorization.
Hybrid setups, where retrieval happens selectively or through cached context, often provide the best of both worlds: accuracy without heavy compute costs.

How to Build AI Agents That Actually Use Your Data
Building effective AI agents starts with one key decision - understanding what data should be retrieved and what should live as memory. Not everything belongs in a vector store; some knowledge is better kept within the model’s internal context for faster access.
Next comes the foundation: embeddings, vector storage, and retrieval pipelines. The process involves turning data into searchable embeddings, storing them in vector databases, and designing logic to fetch the right context at the right time.
You also need a smart agent wrapper - a layer that decides when to trigger retrieval, how to form search queries, and how to balance accuracy with speed. This is where dynamic context windows, chunking, and reranking strategies keep responses grounded and relevant.
At RT Dynamic, we specialize in building RAG-powered AI agents that actually use your data effectively. From pipeline architecture to real-time retrieval and memory optimization, our solutions are engineered to make your agents precise, explainable, and truly useful.
Best Practices
Building a reliable RAG or No-RAG system is about balancing precision, performance, and scalability. A few well-placed design choices can make or break your agent’s effectiveness.
- Focus on retrieval quality: Choose the right embeddings, vector database, and chunking strategy.
- Manage your context window smartly: Use overlapping or sliding windows to maintain narrative flow.
- Add rerankers and filters: Eliminate irrelevant results before feeding data to the model.
- Enable feedback loops: Log responses, collect user signals, and continuously reindex data.
- Plan fall-backs: If retrieval fails, use cached memory or heuristics to avoid breaking responses.
At RT Dynamic, we emphasize retrieval precision, scalable memory systems, and feedback-driven pipelines that keep RAG agents both fast and grounded.
Common Pitfalls and How to Avoid Them
Even strong RAG setups can stumble when design details are overlooked. These are the traps most teams run into:
- Over-retrieving noise: Pulling too much context can confuse rather than clarify.
- Hidden latency: Retrieval lag can quietly degrade user experience.
- Domain mismatch: Mixing unrelated sources leads to conflicting context.
- Hallucinations still happen: RAG reduces them, but doesn’t eliminate them - add validation layers.
- Security risks: Centralized vector stores can leak data without proper encryption and access control.
- Maintenance overhead: Embeddings decay; schedule periodic reindexing to stay accurate.
A well-architected system is about retrieval as much as it’s about control. Keeping these best practices and pitfalls in mind ensures your AI agents evolve with your data, not against it.

Future of RAG: Self-RAG, Agentic RAG, and Beyond
The next wave of RAG innovation is all about autonomy. We’re moving from static retrieval pipelines to Agentic RAG, where AI agents don’t just generate responses but plan, retrieve, and decide when and how to use knowledge dynamically.
In multi-agent systems like MA-RAG, tasks get divided among specialized agents; one handles retrieval, another ranks results, and a third composes final answers. It’s collaborative intelligence, not just bigger context windows.
Then comes Self-RAG in which architectures that learn from their own retrieval patterns, refining queries and adapting context selection over time. These systems don’t just use data; they evolve with it.
Conclusion
Every architecture choice in AI comes down to a balance between accuracy, simplicity, and performance. RAG brings context and truth; No-RAG brings speed and control. The smartest systems know when to use both.
If you’re starting out, keep it simple. Test retrieval on a small dataset, measure its impact, then scale. The right setup is about aligning technology with your data and goals.
At RT Dynamic, we help teams design and deploy RAG and Agentic AI architectures customized to their needs from proof of concept to full-scale enterprise rollouts. The key isn’t just building agents that talk but ones that truly understand.
At the center of it all lies memory - the connective tissue between retrieval and reasoning. Future RAG agents will blend short-term recall with long-term understanding, creating something that feels less like a chatbot and more like a thinking partner.
FAQs: RAG or No-RAG / AI Agents Using Your Data
What is the difference between RAG and No-RAG agents?
RAG agents use external retrieval systems to fetch real-time, contextually relevant data before responding. No-RAG agents, on the other hand, rely only on what’s stored in the model’s internal memory. The first offers accuracy and transparency; the second delivers speed and simplicity.
2. When should you not use RAG?
Avoid RAG when your data is small, static, or rarely updated. In those cases, retrieval adds unnecessary latency and cost. A fine-tuned No-RAG model can often handle such workloads more efficiently.
Can RAG eliminate hallucinations entirely?
No, but it can dramatically reduce them. Since RAG grounds outputs in real documents, hallucinations become less frequent and easier to detect. Still, response validation and context filtering remain essential.
Do agents slow down because of retrieval latency?
Yes, retrieval adds an extra step, but it can be optimized. Using vector caching, rerankers, and parallel retrieval pipelines helps maintain near real-time performance, even at scale.
How to secure vector databases and avoid data leakage?
Protecting your embeddings and metadata is crucial. Use encryption at rest, role-based access control, and private vector stores where possible. At RT Dynamic, we integrate secure RAG pipelines that safeguard enterprise data end-to-end.



